使用 Instructor 分析 Youtube 转录¶
提取章节信息¶
代码片段
像往常一样,您可以在我们的代码仓库中的 examples/youtube 文件夹下找到代码,供您参考 run.py 文件。
在本文中,我们将展示如何使用 instructor 将 YouTube 视频转录总结成不同的章节,然后探索如何将代码应用于不同的场景。
阅读本文后,您将能够按照下方视频构建一个应用。
首先,让我们安装所需的软件包。
快速备注
本教程中使用的视频是 Jeremy Howard 的 语言模型黑客指南。它的视频 ID 是 jkrNMKz9pWU。
接下来,让我们首先为我们想要的结构化章节信息定义一个 Pydantic 模型。
from pydantic import BaseModel, Field
class Chapter(BaseModel):
start_ts: float = Field(
...,
description="Starting timestamp for a chapter.",
)
end_ts: float = Field(
...,
description="Ending timestamp for a chapter",
)
title: str = Field(
..., description="A concise and descriptive title for the chapter."
)
summary: str = Field(
...,
description="A brief summary of the chapter's content, don't use words like 'the speaker'",
)
我们可以利用 youtube-transcript-api 使用以下函数提取视频的转录本
from youtube_transcript_api import YouTubeTranscriptApi
def get_youtube_transcript(video_id: str) -> str:
try:
transcript = YouTubeTranscriptApi.get_transcript(video_id)
return " ".join(
[f"ts={entry['start']} - {entry['text']}" for entry in transcript]
)
except Exception as e:
print(f"Error fetching transcript: {e}")
return ""
完成后,我们可以将它们整合到以下函数中。
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from youtube_transcript_api import YouTubeTranscriptApi
# Set up OpenAI client
client = instructor.from_openai(OpenAI())
class Chapter(BaseModel):
start_ts: float = Field(
...,
description="The start timestamp indicating when the chapter starts in the video.",
)
end_ts: float = Field(
...,
description="The end timestamp indicating when the chapter ends in the video.",
)
title: str = Field(
..., description="A concise and descriptive title for the chapter."
)
summary: str = Field(
...,
description="A brief summary of the chapter's content, don't use words like 'the speaker'",
)
def get_youtube_transcript(video_id: str) -> str:
try:
transcript = YouTubeTranscriptApi.get_transcript(video_id)
return [f"ts={entry['start']} - {entry['text']}" for entry in transcript]
except Exception as e:
print(f"Error fetching transcript: {e}")
return ""
def extract_chapters(transcript: str):
return client.chat.completions.create_iterable(
model="gpt-4o", # You can experiment with different models
response_model=Chapter,
messages=[
{
"role": "system",
"content": "Analyze the given YouTube transcript and extract chapters. For each chapter, provide a start timestamp, end timestamp, title, and summary.",
},
{"role": "user", "content": transcript},
],
)
if __name__ == "__main__":
transcripts = get_youtube_transcript("jkrNMKz9pWU")
for transcript in transcripts[:2]:
print(transcript)
#> ts=0.539 - hi I am Jeremy Howard from fast.ai and
#> ts=4.62 - this is a hacker's guide to language
formatted_transcripts = ''.join(transcripts)
chapters = extract_chapters(formatted_transcripts)
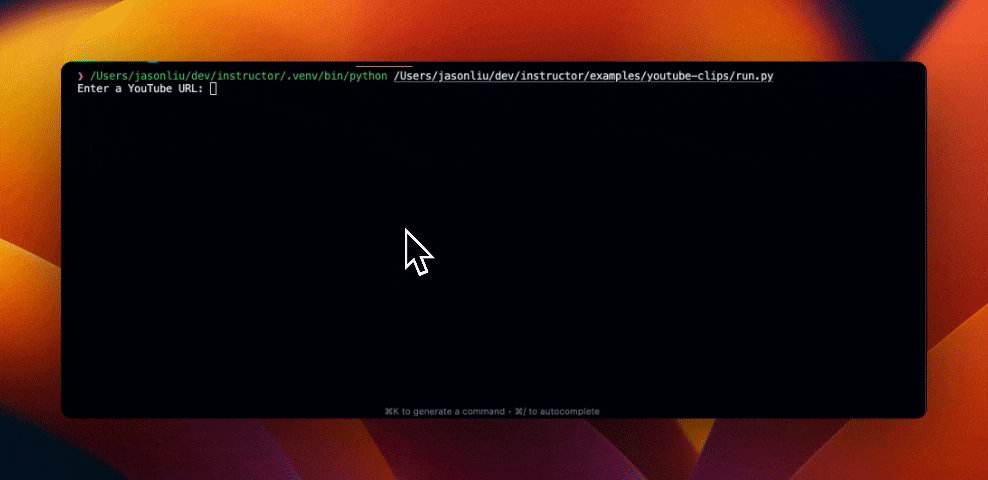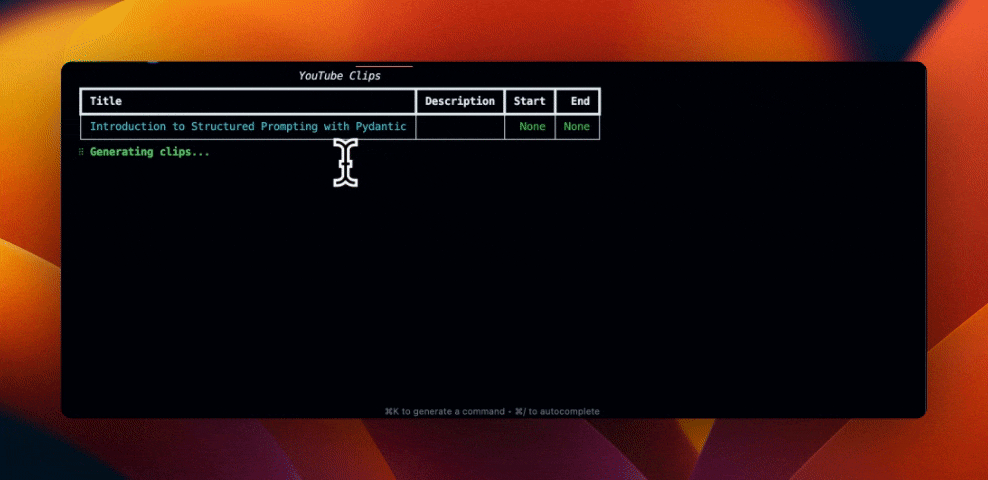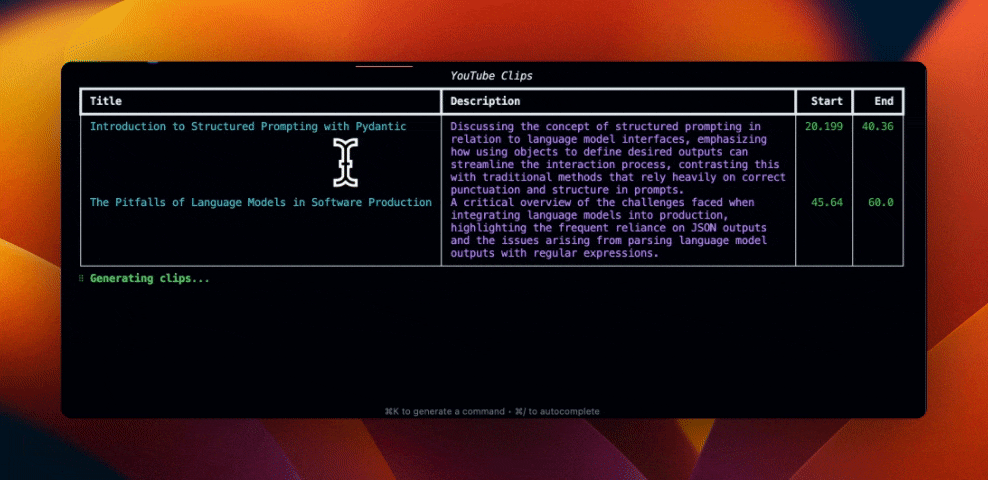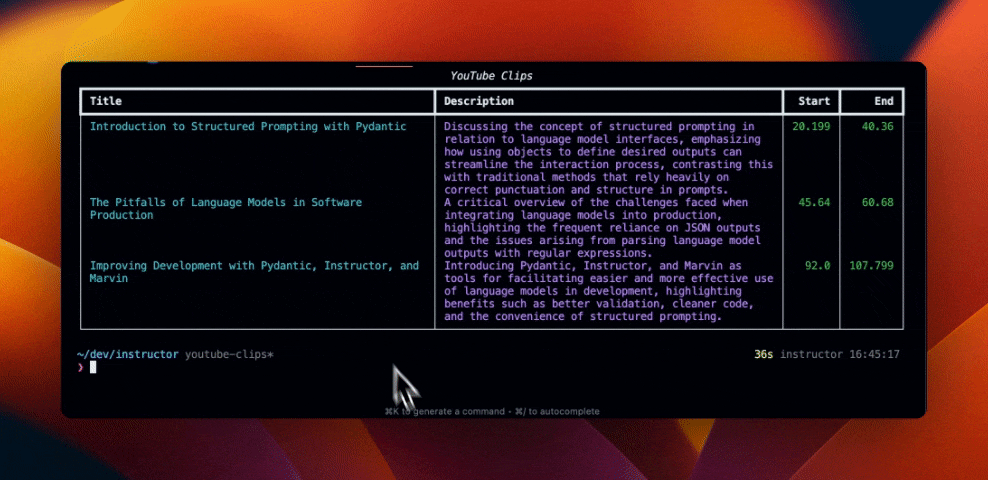
for chapter in chapters:
print(chapter.model_dump_json(indent=2))
"""
{
"start_ts": 0.539,
"end_ts": 9.72,
"title": "Introduction",
"summary": "Jeremy Howard from fast.ai introduces the video, mentioning it as a hacker's guide to language models, focusing on a code-first approach."
}
"""
"""
{
"start_ts": 9.72,
"end_ts": 65.6,
"title": "Understanding Language Models",
"summary": "Explains the code-first approach to using language models, suggesting prerequisites such as prior deep learning knowledge and recommends the course.fast.ai for in-depth learning."
}
"""
"""
{
"start_ts": 65.6,
"end_ts": 250.68,
"title": "Basics of Language Models",
"summary": "Covers the concept of language models, demonstrating how they predict the next word in a sentence, and showcases OpenAI's text DaVinci for creative brainstorming with examples."
}
"""
"""
{
"start_ts": 250.68,
"end_ts": 459.199,
"title": "How Language Models Work",
"summary": "Dives deeper into how language models like ULMfit and others were developed, their training on datasets like Wikipedia, and the importance of learning various aspects of the world to predict the next word effectively."
}
"""
# ... other chapters
替代想法¶
既然我们已经看到了章节提取的完整示例,接下来我们将探索使用不同 Pydantic 模型的一些替代想法。这些模型可以用于将我们的 YouTube 转录分析应用于各种场景。
1. 学习笔记生成器¶
from pydantic import BaseModel, Field
from typing import List
class Concept(BaseModel):
term: str = Field(..., description="A key term or concept mentioned in the video")
definition: str = Field(
..., description="A brief definition or explanation of the term"
)
class StudyNote(BaseModel):
timestamp: float = Field(
..., description="The timestamp where this note starts in the video"
)
topic: str = Field(..., description="The main topic being discussed at this point")
key_points: List[str] = Field(..., description="A list of key points discussed")
concepts: List[Concept] = Field(
..., description="Important concepts mentioned in this section"
)
该模型将视频内容组织成清晰的主题、要点和重要概念,非常适合复习和学习。
2. 内容总结¶
from pydantic import BaseModel, Field
from typing import List
class ContentSummary(BaseModel):
title: str = Field(..., description="The title of the video")
duration: float = Field(
..., description="The total duration of the video in seconds"
)
main_topics: List[str] = Field(
..., description="A list of main topics covered in the video"
)
key_takeaways: List[str] = Field(
..., description="The most important points from the entire video"
)
target_audience: str = Field(
..., description="The intended audience for this content"
)
该模型提供了整个视频的高级概述,非常适合快速内容分析或决定是否值得完整观看视频。
3. 测验生成器¶
from pydantic import BaseModel, Field
from typing import List
class QuizQuestion(BaseModel):
question: str = Field(..., description="The quiz question")
options: List[str] = Field(
..., min_items=2, max_items=4, description="Possible answers to the question"
)
correct_answer: int = Field(
...,
ge=0,
lt=4,
description="The index of the correct answer in the options list",
)
explanation: str = Field(
..., description="An explanation of why the correct answer is correct"
)
class VideoQuiz(BaseModel):
title: str = Field(
..., description="The title of the quiz, based on the video content"
)
questions: List[QuizQuestion] = Field(
...,
min_items=5,
max_items=20,
description="A list of quiz questions based on the video content",
)
该模型将视频内容转化为互动测验,非常适合测试理解能力或为社交媒体创建引人入胜的内容。
要使用这些替代模型,您需要在原始代码中用这些替代模型之一替换 Chapter 模型,并相应地调整 extract_chapters 函数中的系统提示词。
结论¶
这种方法的强大之处在于其灵活性。通过将函数调用的结果定义为 Pydantic 模型,我们可以快速地将代码适应各种应用,无论是生成测验、创建学习材料,还是仅仅为了简单的 SEO 进行优化。