使用 Langfuse 进行可观测性与追踪¶
什么是 Langfuse?
什么是 Langfuse? Langfuse (GitHub) 是一个开源的 LLM 工程平台,帮助团队追踪 API 调用、监控性能并调试其 AI 应用中的问题。
本教程展示了如何使用 Langfuse 来追踪和监控使用 Instructor 库进行的模型调用。
设置¶
注意:在继续本节之前,请确保您已注册 Langfuse 帐户。您将需要您的私钥和公钥才能开始使用 Langfuse 进行追踪。
首先,让我们安装必要的依赖项。
使用 instructor 与 Langfuse 集成非常简单。我们使用 Langfuse OpenAI 集成,只需使用 instructor 修补客户端即可。这适用于同步和异步客户端。
Langfuse-Instructor 与同步 OpenAI 客户端集成¶
import instructor
from langfuse.openai import openai
from pydantic import BaseModel
import os
# Set your API keys Here
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-..."
os.environ["LANGFUSE_SECRET_KEY"] = "sk-..."
os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com"
os.environ["OPENAI_API_KEY] = "sk-..."
# Patch Langfuse wrapper of synchronous OpenAI client with instructor
client = instructor.from_openai(openai.OpenAI())
class WeatherDetail(BaseModel):
city: str
temperature: int
# Run synchronous OpenAI client
weather_info = client.chat.completions.create(
model="gpt-4o",
response_model=WeatherDetail,
messages=[
{"role": "user", "content": "The weather in Paris is 18 degrees Celsius."},
],
)
print(weather_info.model_dump_json(indent=2))
"""
{
"city": "Paris",
"temperature": 18
}
"""
成功运行此请求后,您将在 Langfuse 控制面板中看到可用的追踪信息供您查看。
Langfuse-Instructor 与异步 OpenAI 客户端集成¶
import instructor
from langfuse.openai import openai
from pydantic import BaseModel
import os
import asyncio
# Set your API keys Here
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-"
os.environ["LANGFUSE_SECRET_KEY"] = "sk-"
os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com"
os.environ["OPENAI_API_KEY] = "sk-..."
# Patch Langfuse wrapper of synchronous OpenAI client with instructor
client = instructor.from_openai(openai.AsyncOpenAI())
class WeatherDetail(BaseModel):
city: str
temperature: int
async def main():
# Run synchronous OpenAI client
weather_info = await client.chat.completions.create(
model="gpt-4o",
response_model=WeatherDetail,
messages=[
{"role": "user", "content": "The weather in Paris is 18 degrees Celsius."},
],
)
print(weather_info.model_dump_json(indent=2))
"""
{
"city": "Paris",
"temperature": 18
}
"""
asyncio.run(main())
这是我们生成的追踪的公共链接,您可以在 Langfuse 中查看。
示例¶
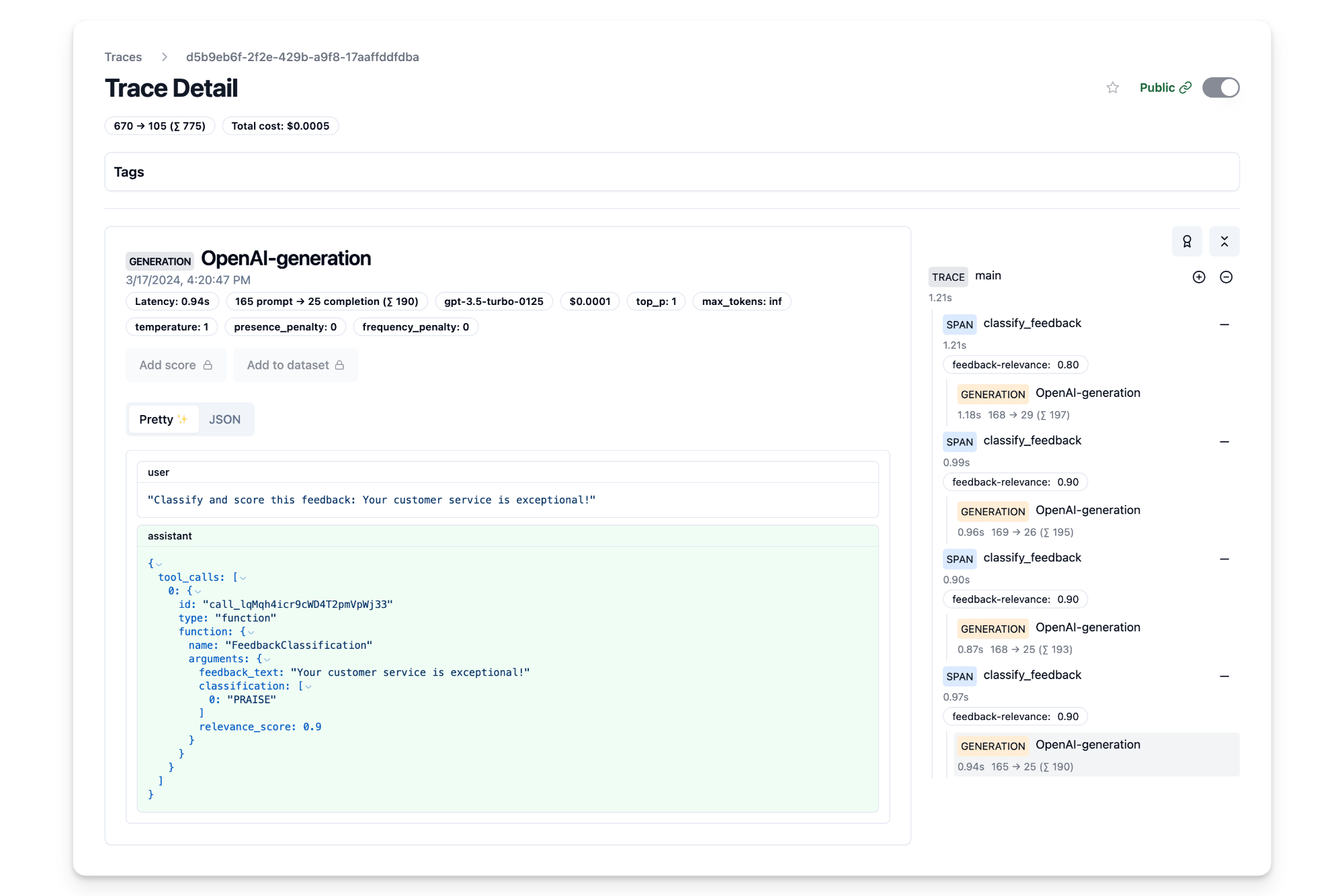
在此示例中,我们首先将客户反馈分类为 PRAISE(赞扬)、SUGGESTION(建议)、BUG(错误)和 QUESTION(问题)等类别,并进一步评估每条反馈与业务的相关性(范围从 0.0 到 1.0)。在此情况下,我们使用异步 OpenAI 客户端 AsyncOpenAI 对反馈进行分类和评估。
from enum import Enum
import asyncio
import instructor
from langfuse import Langfuse
from langfuse.openai import AsyncOpenAI
from langfuse.decorators import langfuse_context, observe
from pydantic import BaseModel, Field, field_validator
import os
# Set your API keys Here
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-..."
os.environ["LANGFUSE_SECRET_KEY"] = "sk-..."
os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com"
os.environ["OPENAI_API_KEY] = "sk-..."
client = instructor.from_openai(AsyncOpenAI())
# Initialize Langfuse (needed for scoring)
langfuse = Langfuse()
# Rate limit the number of requests
sem = asyncio.Semaphore(5)
# Define feedback categories
class FeedbackType(Enum):
PRAISE = "PRAISE"
SUGGESTION = "SUGGESTION"
BUG = "BUG"
QUESTION = "QUESTION"
# Model for feedback classification
class FeedbackClassification(BaseModel):
feedback_text: str = Field(...)
classification: list[FeedbackType] = Field(
description="Predicted categories for the feedback"
)
relevance_score: float = Field(
default=0.0,
description="Score of the query evaluating its relevance to the business between 0.0 and 1.0",
)
# Make sure feedback type is list
@field_validator("classification", mode="before")
def validate_classification(cls, v):
if not isinstance(v, list):
v = [v]
return v
@observe() # Langfuse decorator to automatically log spans to Langfuse
async def classify_feedback(feedback: str):
"""
Classify customer feedback into categories and evaluate relevance.
"""
async with sem: # simple rate limiting
response = await client.chat.completions.create(
model="gpt-4o",
response_model=FeedbackClassification,
max_retries=2,
messages=[
{
"role": "user",
"content": f"Classify and score this feedback: {feedback}",
},
],
)
# Retrieve observation_id of current span
observation_id = langfuse_context.get_current_observation_id()
return feedback, response, observation_id
def score_relevance(trace_id: str, observation_id: str, relevance_score: float):
"""
Score the relevance of a feedback query in Langfuse given the observation_id.
"""
langfuse.score(
trace_id=trace_id,
observation_id=observation_id,
name="feedback-relevance",
value=relevance_score,
)
@observe() # Langfuse decorator to automatically log trace to Langfuse
async def main(feedbacks: list[str]):
tasks = [classify_feedback(feedback) for feedback in feedbacks]
results = []
for task in asyncio.as_completed(tasks):
feedback, classification, observation_id = await task
result = {
"feedback": feedback,
"classification": [c.value for c in classification.classification],
"relevance_score": classification.relevance_score,
}
results.append(result)
# Retrieve trace_id of current trace
trace_id = langfuse_context.get_current_trace_id()
# Score the relevance of the feedback in Langfuse
score_relevance(trace_id, observation_id, classification.relevance_score)
# Flush observations to Langfuse
langfuse_context.flush()
return results
feedback_messages = [
"The chat bot on your website does not work.",
"Your customer service is exceptional!",
"Could you add more features to your app?",
"I have a question about my recent order.",
]
feedback_classifications = asyncio.run(main(feedback_messages))
for classification in feedback_classifications:
print(f"Feedback: {classification['feedback']}")
print(f"Classification: {classification['classification']}")
print(f"Relevance Score: {classification['relevance_score']}")
"""
Feedback: I have a question about my recent order.
Classification: ['QUESTION']
Relevance Score: 0.0
Feedback: Could you add more features to your app?
Classification: ['SUGGESTION']
Relevance Score: 0.0
Feedback: The chat bot on your website does not work.
Classification: ['BUG']
Relevance Score: 0.9
Feedback: Your customer service is exceptional!
Classification: ['PRAISE']
Relevance Score: 0.9
"""
可以看到,借助 Langfuse,我们能够生成这些不同的补全结果并在我们自己的用户界面中查看它们。点击此处查看我们生成的 5 个补全结果的公共追踪。