优先选择一致的示例
基于一致性的自适应提示 (Consistency Based Self Adaptive Prompting, COSP)1 旨在通过生成高质量的少样本示例来提高 LLM 输出质量,这些示例将被包含在最终的 Prompt 中。这些示例没有标注的真实标签,因此它们使用自洽性和一个称为归一化熵的指标来选择最佳示例。
选择好示例后,他们将这些示例附加到 Prompt 中,并生成多个推理链,然后使用自洽性选择最终结果。
COSP 流程¶
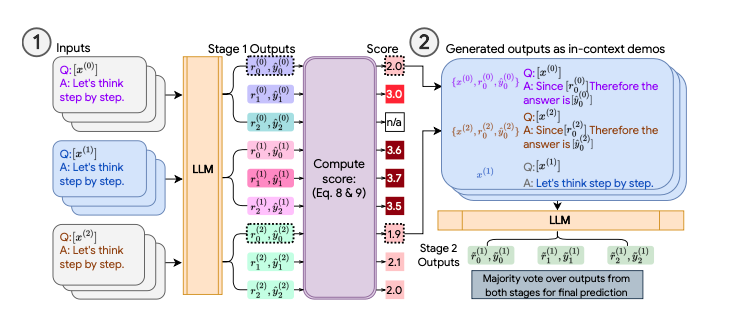
这在实践中如何体现?让我们深入了解详情。
步骤 1 - 选择示例¶
第一步是尝试从没有真实标签的问题生成高质量示例。这很有挑战性,因为我们需要找到一种方法,在对模型多次采样时自动确定答案的质量。
在这种情况下,我们有 n 个问题,我们希望为每个问题生成 m 个可能的推理链。这样总共有 nm 个示例。然后,我们希望从这 nm 个示例中筛选出 k 个最终的少样本示例,将其包含在最终的 Prompt 中。
- 使用思维链,我们首先为每个问题生成
m个响应。这些响应包含最终答案及其背后的理由。 - 我们使用两个值的加权和来计算每个响应的分数 - 归一化熵和重复性(此理由对此答案出现的次数)
- 我们使用这个分数对所有
nm个响应进行排序,并选择分数最低的k个示例作为最终的少样本示例。
归一化熵¶
在论文中,作者写道,归一化熵在许多不同任务中是一个很好的代理指标,其中低熵与正确性呈正相关。熵的取值范围也应该在 0 到 1 之间。
因此,为了做到这一点,我们在实现中引入了一个
-项,以便计算出的值范围在 0 到 1 之间。
假设对于特定问题 \(x^{(i)}\),我们生成了 \(m\) 个最终答案,其中 \(u\) 个是唯一的。(注意,这只关注答案本身,而不关注理由)
我们可以使用上面的公式测量生成响应的熵,其中
- \(x_i\) 是我们用来提示模型的原始问题
- \(y_j^{i}\) 表示我们在生成的 \(m\) 个响应中的第 \(i\) 个采样响应
- \(\hat{p}\left(\hat{y}_{\alpha}^{(i)}\right)\) 是所有 \(m\) 个生成答案中唯一答案的频率。(例如,如果我们生成 8 个响应,其中 4 个返回值为 10,那么 \(\hat{p}\left(\hat{y}_{\alpha}^{(i)}\right)\) 就等于 0.5)
重复性¶
在上面的公式中,\(Q\) 指代句子中的短语数量,\(W_{ab}\) 指代两个短语 \(a\) 和 \(b\) 的余弦相似度。
重复性旨在衡量语言模型重复自身的频率。为此,该论文在归一化之前,对生成的思维链理由中每个句子之间的余弦相似度进行了求和。
这背后的直觉是,高重复性表明存在冗余,这可能导致性能下降。因此,包含大量相似句子的响应将具有更高的重复性得分(因为每个句子之间的余弦相似度会更大)。
步骤 2 - 自洽性¶
现在我们取 k 个响应并将其附加到我们的 Prompt 中。然后使用这个新的 Prompt 对模型进行多次采样,并以多数投票的结果作为答案。
实现¶
现在我们了解了 COSP 是什么,来看看如何在 instructor 中实现它。注意,这里我们将使用句子嵌入之间的余弦相似度来衡量重复性。
import instructor
from pydantic import BaseModel
from openai import AsyncOpenAI, OpenAI
from collections import defaultdict, Counter
import asyncio
from textwrap import dedent
import math
client = instructor.from_openai(AsyncOpenAI())
class Response(BaseModel):
chain_of_thought: list[str]
answer: int
class ResponseScore(BaseModel):
query: str
response: Response
score: float
def format_response(self):
return dedent(
f"""
Q: {self.query}
A: {''.join(self.response.chain_of_thought)}. Therefore the answer is {self.response.answer}.
"""
)
def cosine_similarity(vec1: list[float], vec2: list[float]):
dot_product = sum(a * b for a, b in zip(vec1, vec2))
magnitude1 = math.sqrt(sum(a * a for a in vec1))
magnitude2 = math.sqrt(sum(b * b for b in vec2))
if magnitude1 * magnitude2 == 0:
return 0 # Handle the case of zero vectors
return dot_product / (magnitude1 * magnitude2)
def score_repetitiveness(prediction: Response):
if len(prediction.chain_of_thought) == 1:
return 0
embedding = OpenAI().embeddings.create(
input=prediction.chain_of_thought, model="text-embedding-3-small"
)
embedding = [item.embedding for item in embedding.data]
ttl = 0
num_comparisons = 0
for idx in range(len(embedding)):
for idx2 in range(idx + 1, len(embedding)):
ttl += cosine_similarity(embedding[idx], embedding[idx2])
num_comparisons += 1
return ttl / num_comparisons if num_comparisons > 0 else 0
async def generate_cot_response(query: str) -> tuple[Response, str]:
return (
await client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": query}],
response_model=Response,
temperature=0.4,
),
query,
)
async def generate_batch_cot_responses(
queries: list[str], m: int
) -> list[tuple[Response, str]]:
coros = [generate_cot_response(query) for query in queries for _ in range(m)]
return await asyncio.gather(*coros)
def score_entropy(predictions: list[Response]):
counter = Counter([prediction.answer for prediction in predictions])
prob = [counter[i] / len(predictions) for i in counter]
numer = -sum([p * math.log(p) for p in prob])
denom = math.log(len(predictions))
return numer / denom
def score_responses(
predictions: list[tuple[Response, str]], trade_off_param: float
) -> list[ResponseScore]:
query_to_responses: dict[str, list[Response]] = defaultdict(list)
for prediction, query in predictions:
query_to_responses[query].append(prediction)
query_to_entropy = {
query: score_entropy(predictions)
for query, predictions in query_to_responses.items()
}
return [
ResponseScore(
query=query,
response=prediction,
score=query_to_entropy[query]
+ trade_off_param * score_repetitiveness(prediction),
)
for prediction, query in predictions
]
def get_top_k_examples(queries: list[ResponseScore], k: int):
"""
This gets the top k responses that have the minimum possible score
"""
sorted_responses = sorted(queries, key=lambda x: x.score)
return sorted_responses[:k]
async def generate_answer_with_examples(query: str, examples: list[ResponseScore]):
formatted_examples = "\n".join([example.format_response() for example in examples])
return await client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": dedent(
f"""
You are a world class AI system that excels at answering user queries
<query>
{query}
</query>
<examples>
{formatted_examples}
</examples>
"""
),
}
],
response_model=Response,
)
async def generate_final_answers(
query: str, examples: list[ResponseScore], number_samples: int
):
coros = [
generate_answer_with_examples(query, examples) for _ in range(number_samples)
]
return await asyncio.gather(*coros)
if __name__ == "__main__":
query = (
"The schools debate team had 5 boys and 40 girls on it. "
"If they were split into groups of 9 how many groups "
"could they make?"
)
example_questions = [
(
"Debby's class is going on a field trip to the zoo. "
"If each van can hold 4 people and there are 2 students "
"and 6 adults going, how many vans will they need?"
),
(
"Nancy had 80 files on her computer. She deleted 31 of "
"them and put the rest into folders with 7 files in each "
"one. How many folders did Nancy end up with?"
),
(
"At the arcade, Tom won 32 tickets playing 'whack a mole' "
"and 25 tickets playing 'skee ball'. If he spent 7 of his "
"tickets on a hat, how many tickets does Tom have left?"
),
]
m = 2 # Number of Reasoning Chains per example ( Step 1 )
k = 3 # Number of Examples to include in final prompt (Step 2)
n = 2 # Number of Reasoning Chains For Self-Consistency ( Step 2 )
# Step 1 : Generate the examples
responses = asyncio.run(generate_batch_cot_responses(example_questions, m))
scored_responses = score_responses(responses, 0.2)
chosen_examples = get_top_k_examples(scored_responses, k)
# Step 2 : Run Self-Consistency
final_responses = asyncio.run(generate_final_answers(query, chosen_examples, n))
c = Counter([response.answer for response in final_responses])
answer = c.most_common(1)[0][0]
print(answer)
#> 5