使用集成方法测试提示词
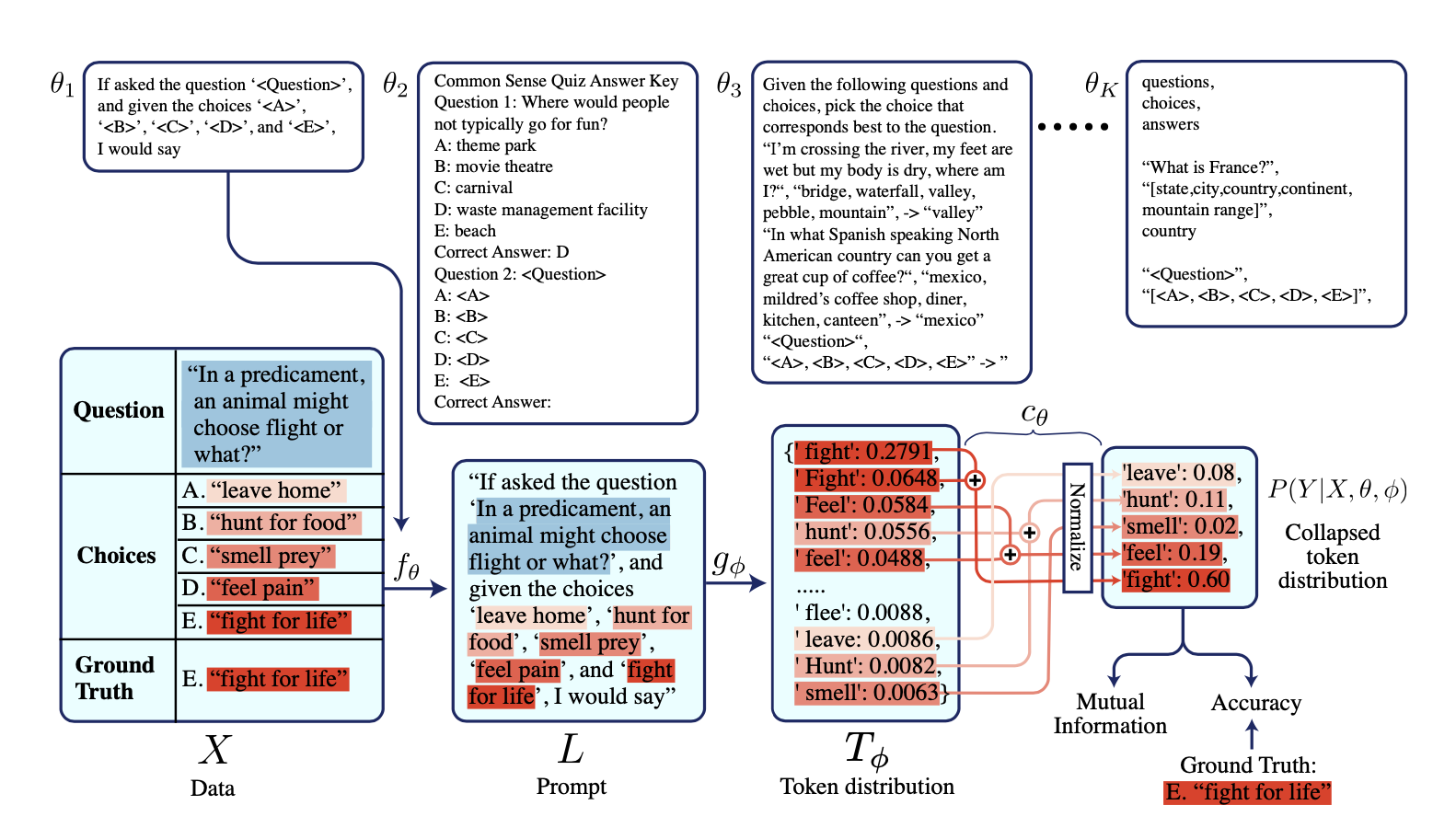
什么是最大互信息?¶
最大互信息方法是一种旨在找到最佳提示词以从大型语言模型 (LLM) 获得所需响应的提示方法。我们通过最大化一个称为互信息的指标来做到这一点——该指标表示模型由于提示词而带来的不确定性降低。
熵¶
当语言模型接收提示词作为输入时,它会按顺序输出一系列 token 概率,直到到达 `
当我们有一个概率分布时,我们可以计算一个称为熵的概率值。这个值越低越好。这是因为较低的熵值意味着模型对其预测更有信心。
我们可以用以下公式计算熵,其中 \(P(T_i)\) 表示最终输出分布中第 \(i\) 个 token 的概率。
互信息¶
我们可以将此应用于上面看到的互信息计算。
我们将概率分布的熵计算表示为 \(H(X)\),其中 \(X\) 在此处表示最终概率分布。我们还假设您有一个包含 \(n\) 个示例的训练数据集可以使用。
-
首先,我们选择一组很可能属于最终答案的 token。这可能是我们提供的选项中出现的词语。
-
选择这些 token 后,我们从最终分布中提取每个 token 的对数概率。然后对其进行归一化,使这些新的对数概率总和为 1。
-
我们对训练集中的第 \(n\) 个示例执行此操作,这为每个第 \(i\) 个示例提供了一个新的分布 \(P(Y_i|X_i)\)。
-
然后我们对这 \(n\) 个分布取平均值以获得 \(H_{marginal}\)
-
然后我们计算每个分布的熵的平均值以获得 \(H_{conditional}\)
-
然后我们通过计算 \(H_{marginal} - H_{conditional}\) 来得出互信息,这个指标越高越好。
不确定如何计算 \(H_{marginal}\) 和 \(H\_{conditional}\)
然后我们可以使用这个新的互信息指标来比较不同提示词在从我们的训练数据集中获得所需响应方面的有效性。
实现¶
由于我们无法在 OpenAI API 中直接访问我们想要的特定 token 的原始对数概率,我们将改为让语言模型生成一个 1 到 10 的最终分数,表示其对其预测的置信度。
然后,我们将其转换为包含两个结果的概率分布,并据此计算一个熵值。
接下来,我们将比较不同提示词的互信息值,然后选择最佳提示词。在本示例中,我们将使用 Story Cloze 数据集中的值。
from openai import AsyncOpenAI
from instructor import from_openai
from pydantic import BaseModel
from typing import Callable, Literal
from textwrap import dedent
import math
import asyncio
class Response(BaseModel):
chain_of_thought: str
response: Literal["A", "B"]
confidence: Literal[
"Very High Confidence",
"High Confidence",
"Moderate Confidence",
"Low Confidence",
"Very Low Confidence",
]
def generate_score(self) -> float:
confidence_scores = {
"Very High Confidence": 1,
"High Confidence": 0.8,
"Moderate Confidence": 0.6,
"Low Confidence": 0.4,
"Very Low Confidence": 0.2,
}
return confidence_scores[self.confidence]
client = from_openai(AsyncOpenAI())
def prompt_template_1(question: str, options: list[str]):
assert len(options) == 2
a, b = options
return dedent(
f"""
You are a world class AI System which excels at understanding complex user stories and generating responses. Output your prediction and also quantify your confidence in your prediction with the following scale.
- Very High Confidence: The model is highly confident in its prediction, displaying deep understanding, flawless execution, and no noticeable errors.
- High Confidence: The model is confident in its prediction, with strong relevance and minor errors that do not detract from overall quality.
- Moderate Confidence: The model has moderate confidence in its prediction, which is generally relevant with some inaccuracies, and meets minimum requirements.
- Low Confidence: The model has low confidence in its prediction, with limited relevance and several inaccuracies.
- Very Low Confidence: The model has very low confidence in its prediction, which is largely irrelevant, inaccurate, or incomplete, needing significant improvement
Context
{question}
Options
A. {a}
B. {b}
"""
)
def prompt_template_2(question: str, options: list[str]):
assert len(options) == 2
a, b = options
return dedent(
f"""
<prompt>
<Task>
You are about to be passed a story. You are to select the correct response from the options provided.
<confidence-levels>
<level>
<name>Very High Confidence</name>
<description>The model is highly confident in its prediction, displaying deep understanding, flawless execution, and no noticeable errors.</description>
</level>
<level>
<name>High Confidence</name>
<description>The model is confident in its prediction, with strong relevance and minor errors that do not detract from overall quality.</description>
</level>
<level>
<name>Moderate Confidence</name>
<description>The model has moderate confidence in its prediction, which is generally relevant with some inaccuracies, and meets minimum requirements.</description>
</level>
<level>
<name>Low Confidence</name>
<description>The model has low confidence in its prediction, with limited relevance and several inaccuracies.</description>
</level>
<level>
<name>Very Low Confidence</name>
<description>The model has very low confidence in its prediction, which is largely irrelevant, inaccurate, or incomplete, needing significant improvement</description>
</level>
</confidence-levels>
</Task>
<Question>
{question}
</Question>
<Options>
<option>A: {a}</option>
<option>B: {b}</option>
</Options>
</prompt>
"""
)
async def generate_response(
question: str, options: list[str], prompt_template: Callable[[str, list[str]], str]
):
return await client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": prompt_template(question, options),
}
],
response_model=Response,
)
async def generate_responses(
questions: list[str], prompt_template: Callable[[str, list[str]], str]
):
return await asyncio.gather(
*[
generate_response(
question=question["question"],
options=question["options"],
prompt_template=prompt_template,
)
for question in questions
]
)
def calculate_entropy(probs: list[float]) -> float:
return sum([p * math.log(p) if p != 0 else 0 for p in probs])
def calculate_mutual_information(predictions: list[Response]) -> float:
probs = [
[prediction.generate_score(), 1 - prediction.generate_score()]
for prediction in predictions
]
avg_probs = [0, 0]
for p1, p2 in probs:
avg_probs[0] += p1
avg_probs[1] += p2
h_marginal = calculate_entropy([i / len(probs) for i in avg_probs])
h_conditional = sum([calculate_entropy(prob) for prob in probs]) / len(probs)
return h_marginal - h_conditional
if __name__ == "__main__":
queries = [
{
"question": "Karen was assigned a roommate her first year of college. Her roommate asked her to go to a nearby city for a concert. Karen agreed happily. The show was absolutely exhilarating.",
"options": [
"Karen became good friends with her roommate.",
"Karen hated her roommate.",
],
},
{
"question": "Jim got his first credit card in college. He didn’t have a job so he bought everything on his card. After he graduated he amounted a $10,000 debt. Jim realized that he was foolish to spend so much money. ",
"options": [
"Jim decided to devise a plan for repayment.",
"Jim decided to open another credit card.",
],
},
{
"question": "Gina misplaced her phone at her grandparents. It wasn’t anywhere in the living room. She realized she was in the car before. She grabbed her dad’s keys and ran outside.",
"options": [
"She found her phone in the car.",
"She didn’t want her phone anymore.",
],
},
]
best_mi_score = float("-inf")
best_template = None
for prompt_template in [prompt_template_1, prompt_template_2]:
responses = asyncio.run(generate_responses(queries, prompt_template))
mi_score = calculate_mutual_information(responses)
print(f"{prompt_template.__name__}: {mi_score}")
#> prompt_template_1: -0.0781292189485728
#> prompt_template_2: -0.05907285153542691
if mi_score > best_mi_score:
best_mi_score = mi_score
best_template = prompt_template.__name__
print(best_template, best_mi_score)
#> prompt_template_2 -0.05907285153542691