使用任务特定评估指标
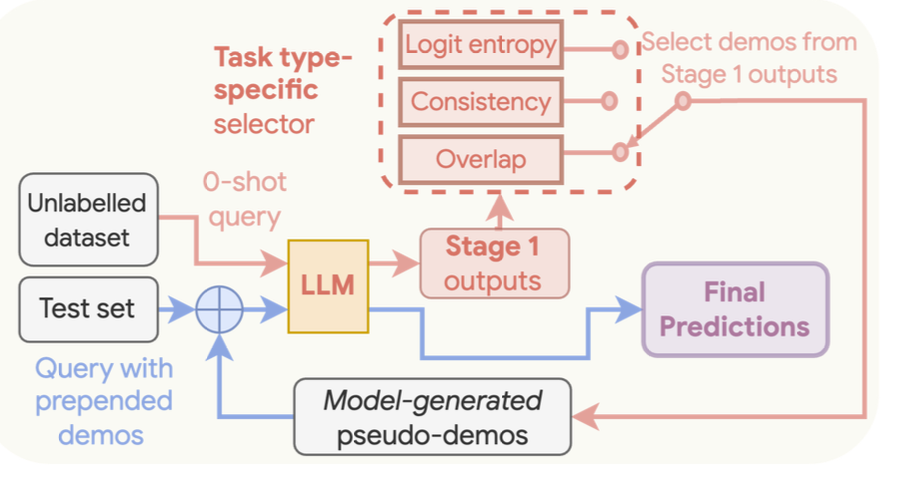
通用自我提示(Universal Self Prompting)是一个两阶段过程,类似于基于一致性的自适应提示(Consistency Based Self Adaptive Prompting, COSP)。以下是这两个阶段的分解。
- 生成示例:提示大型语言模型(LLMs)使用测试数据集生成候选响应集合
- 回答查询:然后我们选择一些由模型生成的响应作为示例来提示大型语言模型,以获得最终预测。
这里请注意,最终答案是使用单次前向传递和贪婪解码获得的。
USP 流程¶
让我们更详细地了解它是如何工作的。
生成少样本示例¶
我们首先提示模型为给定的一组提示生成响应。与 COSP 中衡量熵和重复性不同,我们使用三种可能的方法之一来衡量生成响应的质量。这些方法根据支持的三种类别确定。
用户需要提前指定这个类别。
请注意,对于短格式和长格式生成,我们生成 \(m\) 个不同的样本。分类任务则不是这样。
- 分类:分类任务使用大型语言模型(LLM)原始 logits 的每个标签的归一化概率进行评估。
\[ F_{CLS}(p^{(j)}|d^{(j)}) := -\sum_{c \in C} P(c|d^{(j)}) \log P(c|d^{(j)}) \]
简而言之,我们取对应于标签的每个 token 的原始 logit,使用 softmax 对它们进行归一化,然后对各个概率及其 log probs 进行求和。我们还尝试采样足够的查询,以便在每个类别中都有平衡数量的预测(这样我们的模型就不会偏向特定类别)。
- 短格式生成:这通过使用类似于 COSP 的公式完成,但不包含归一化项
\[ \mathcal{H}\left(x^{(i)} \mid \left\{\hat{y}_j^{(i)}\right\}_{j=1}^m\right) = \frac{\sum_{\alpha=1}^u \hat{p}\left(\hat{y}_{\alpha}^{(i)}\right) \log \hat{p}\left(\hat{y}_{\alpha}^{(i)}\right)}{\log m}, \]
- 长格式生成:这通过使用 \(m\) 个响应的所有配对之间的平均成对 ROUGE 分数完成。
这里的关键在于,根据用户指定的任务,我们有一种任务特定的评估形式。这最终使我们能够更好地评估单个生成的示例。每个类别的任务示例包括:
- 分类:自然语言推理、主题分类和情感分析
- 短格式生成:问答和句子补全
- 长格式生成:文本摘要和机器翻译
这最终有助于提高这些大型语言模型在不同类型任务中的性能。
生成单一响应¶
一旦我们选择了示例,第二步相对简单。我们只需要将我们选择的、在我们选择的指标上得分最高的几个示例附加到我们的解决方案中。
实现¶
我们在下面实现了一个分类示例,该示例尝试在生成响应之前以平衡的方式跨不同类别进行采样,使用单次推理调用。
我们通过使用置信度标签,使采样偏向模型更自信的样本。
from pydantic import BaseModel
from typing import Literal
from instructor import from_openai
from openai import AsyncOpenAI
import asyncio
from collections import defaultdict
class Classification(BaseModel):
chain_of_thought: str
label: Literal["Happy", "Angry", "Sadness"]
confidence: Literal[
"Uncertain", "Somewhat Confident", "Confident", "Highly Confident"
]
def confidence_score(self) -> int:
confidence_order = {
"Highly Confident": 4,
"Confident": 3,
"Somewhat Confident": 2,
"Uncertain": 1,
}
return confidence_order[self.confidence]
client = from_openai(AsyncOpenAI())
async def generate_prediction(query: str):
return (
await client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "user",
"content": f"""Classify the following query {query} into
one of the following categories: Happy, Angry, Sadness""",
}
],
response_model=Classification,
),
query,
)
async def generate_predictions(queries: list[str]) -> list[tuple[Classification, str]]:
return await asyncio.gather(*[generate_prediction(query) for query in queries])
def get_balanced_sample(predictions: list[tuple[Classification, str]], k: int):
label_to_queries: dict[str, list[tuple[Classification, str]]] = defaultdict(list)
for prediction in predictions:
label_to_queries[prediction[0].label].append(prediction)
num_classes = len(label_to_queries)
num_samples_per_class = k // num_classes
res: list[str] = []
for label, label_queries in label_to_queries.items():
label_queries = sorted(
label_queries, key=lambda x: x[0].confidence_score(), reverse=True
)
label_queries = [
label_queries[1] for label_queries in label_queries[:num_samples_per_class]
]
res.extend([f"{query} ({label})" for query in label_queries])
return res
async def generate_response_with_examples(query: str, examples: list[str]):
formatted_examples = "\n".join(examples)
return await client.chat.completions.create(
model="gpt-4o",
response_model=Classification,
messages=[
{
"role": "system",
"content": f"""
You are a helpful assistant that classifies queries into one of the following categories: Happy, Angry, Sadness.
Here are some samples of queries and their categories:
<examples>
{formatted_examples}
</examples>
Here is a user query to classify
<query>
{query}
</query>
""",
},
],
)
if __name__ == "__main__":
examples = [
"""
i do feel that running is a divine experience and
that i can expect to have some type of spiritual
encounter
""",
"""
i get giddy over feeling elegant in a perfectly
fitted pencil skirt
""",
"""
i plan to share my everyday life stories traveling
adventures inspirations and handmade creations with
you and hope you will also feel inspired
""",
"""
i need to feel the dough to make sure its just
perfect
""",
"""
i found myself feeling a little discouraged that
morning
""",
"i didnt really feel that embarrassed",
"i feel like a miserable piece of garbage",
"""
i feel like throwing away the shitty piece of shit
paper
""",
"""
i feel irritated and rejected without anyone doing
anything or saying anything
""",
"i feel angered and firey",
"""
im feeling bitter today my mood has been strange the
entire day so i guess its that
""",
"i just feel really violent right now",
"i know there are days in which you feel distracted",
]
labels = asyncio.run(generate_predictions(examples))
balanced_sample = get_balanced_sample(labels, 3)
for sample in balanced_sample:
print(sample)
"""
i do feel that running is a divine experience and that i can
expect to have some type of spiritual encounter (Happy)
"""
#> i feel like a miserable piece of garbage (Sadness)
#> i feel like throwing away the shitty piece of shit paper (Angry)
response = asyncio.run(
generate_response_with_examples(
"""
i feel furious that right to life advocates can
and do tell me how to live and die through
lobbying and supporting those politicians
sympathic to their views
""",
balanced_sample,
)
)
print(response.model_dump_json(indent=2))
"""
{
"chain_of_thought": "The user expresses feelings of
anger and frustration specifically directed at right
to life advocates. The language used, such as
'furious,' indicates a high level of emotion
associated with anger.",
"label": "Angry",
"confidence": "Highly Confident"
}
"""