示例排序¶
提示中少样本示例的顺序会影响大型语言模型(LLM)的输出 1234*。考虑在提示中排列这些示例的顺序以获得更好的结果。
选择您的示例¶
根据您的用例,这里有一些您可以考虑用来提高示例质量的不同方法。
组合学¶
最简单的方法之一是手动迭代我们拥有的每个示例,并尝试所有可能的组合。这反过来将使我们能够找到最佳组合。
KATE¶
KATE (k-近邻示例调优) 是一种旨在通过选择最相关的上下文示例来增强 GPT-3 性能的方法。该方法包括:
对于测试集中的每个示例,根据语义相似性检索 K 个最近邻(示例)。在这 K 个示例中,在不同查询中出现频率最高的示例被选为最佳上下文示例。
使用无监督检索器¶
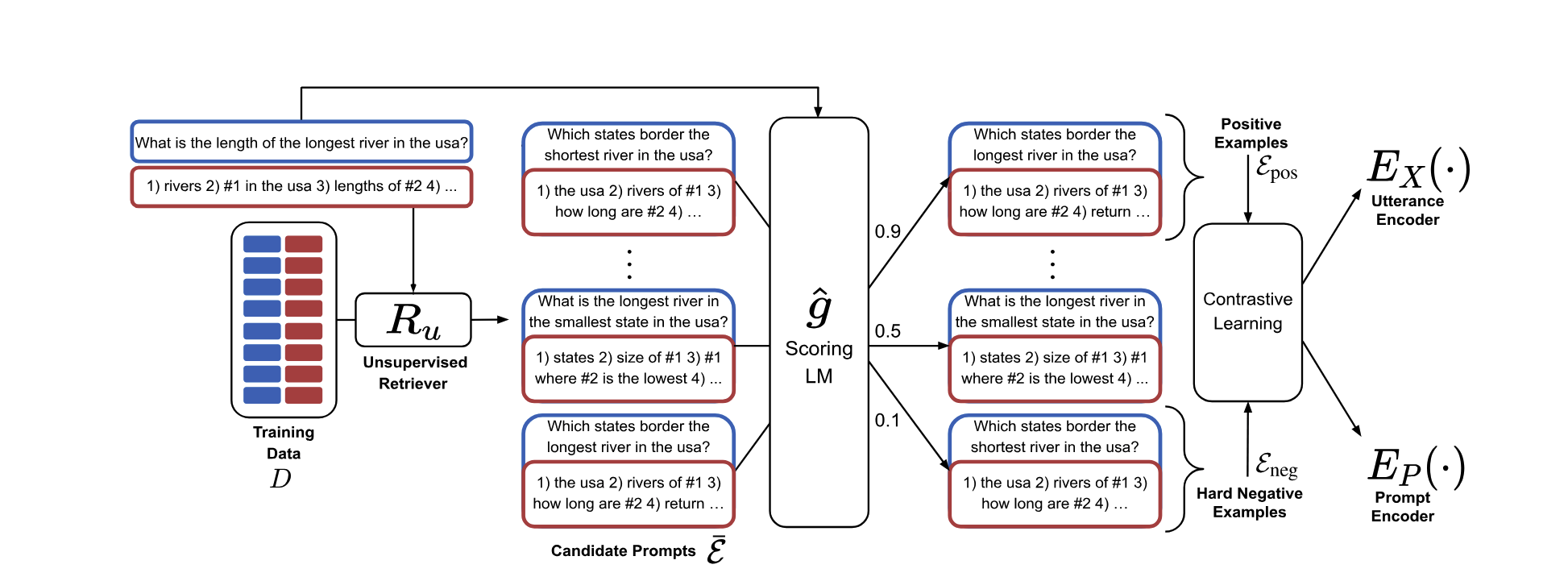
我们可以使用大型语言模型(LLM)为每个示例计算相对于给定提示的单个分数。这使得我们可以创建一个训练集,用于评估示例与提示相比的相关性。利用这个训练集,我们可以训练一个模拟此功能的模型。这使我们能够在用户进行查询时确定排名前 k 的最相关和最不相关的示例,以便将其包含在我们最终的提示中。
参考文献¶
4: 学习检索上下文学习的提示