为什么使用 Instructor?¶
这是 Instructor 的作者 Jason Liu 的一封信。我是 Pydantic 的忠实粉丝,我认为它是处理 Python 数据验证的最佳方式。我多年来一直使用它,很高兴能将它引入 OpenAI API。
为什么使用 Pydantic?
很难回答为什么使用 Instructor 的问题,除非先回答 为什么使用 Pydantic。
-
由类型提示驱动 — 使用 Pydantic,Schema 验证和序列化由类型注解控制;学习内容少,代码量少,并与你的 IDE 和静态分析工具集成。
-
速度 — Pydantic 的核心验证逻辑是用 Rust 编写的。因此,Pydantic 是 Python 中最快的数据验证库之一。
-
JSON Schema — Pydantic 模型可以生成 JSON Schema,便于与其他工具集成。[了解更多…]
-
定制化 — Pydantic 允许使用自定义验证器和序列化器以多种强大的方式改变数据处理方式。
-
生态系统 — PyPI 上约有 8,000 个软件包使用 Pydantic,包括 FastAPI、huggingface、Django Ninja、SQLModel 和 LangChain 等非常流行的库。
-
经受实战考验 — Pydantic 每月下载量超过 7000 万次,被所有 FAANG 公司和纳斯达克市值前 25 大公司中的 20 家使用。如果你正在尝试使用 Pydantic 做某事,很可能已经有人做过了。
无新标准¶
Instructor 构建在 Pydantic 和 OpenAI 之上,这对于许多开发者来说已经很熟悉了。而且,由于许多 LLM 提供商支持 OpenAI API 规范,因此你可以使用许多闭源和开源提供商,例如 Anyscale、Together、Groq、Ollama 和 Llama-cpp-python。
我们所做的就是增强 create 方法,使其能够
查看我们如何连接 开源
使用 Pydantic 而非原始 Schema¶
我发现许多 Prompt 构建工具过于复杂且难以使用,它们可能在简单的例子中很容易上手,但一旦你需要更多控制,你就会希望它们更简单。Instructor 只做了完成工作所需的最少工作。
Pydantic 更易读,定义和引用值都是自动处理的。这对 Instructor 来说是一个巨大的优势,因为它让我们能够专注于数据提取而不是 Schema。
from typing import List, Literal
from pydantic import BaseModel, Field
class Property(BaseModel):
name: str = Field(description="name of property in snake case")
value: str
class Character(BaseModel):
"""
Any character in a fictional story
"""
name: str
age: int
properties: List[Property]
role: Literal['protagonist', 'antagonist', 'supporting']
class AllCharacters(BaseModel):
characters: List[Character] = Field(description="A list of all characters in the story")
你更愿意对这段代码进行代码审查吗?其中所有内容都是字符串,很容易出现拼写错误和引用错误?我知道我不会。
var = {
"$defs": {
"Character": {
"description": "Any character in a fictional story",
"properties": {
"name": {"title": "Name", "type": "string"},
"age": {"title": "Age", "type": "integer"},
"properties": {
"type": "array",
"items": {"$ref": "#/$defs/Property"},
"title": "Properties",
},
"role": {
"enum": ["protagonist", "antagonist", "supporting"],
"title": "Role",
"type": "string",
},
},
"required": ["name", "age", "properties", "role"],
"title": "Character",
"type": "object",
},
"Property": {
"properties": {
"name": {
"description": "name of property in snake case",
"title": "Name",
"type": "string",
},
"value": {"title": "Value", "type": "string"},
},
"required": ["name", "value"],
"title": "Property",
"type": "object",
},
},
"properties": {
"characters": {
"description": "A list of all characters in the story",
"items": {"$ref": "#/$defs/Character"},
"title": "Characters",
"type": "array",
}
},
"required": ["characters"],
"title": "AllCharacters",
"type": "object",
}
易于尝试和安装¶
最小可行 API 只是向客户端添加了 response_model,如果你认为不需要模型,可以很容易地将其删除并继续构建你的应用程序。
import instructor
from openai import OpenAI
from pydantic import BaseModel
# Patch the OpenAI client with Instructor
client = instructor.from_openai(OpenAI())
class UserDetail(BaseModel):
name: str
age: int
# Function to extract user details
def extract_user() -> UserDetail:
user = client.chat.completions.create(
model="gpt-4-turbo-preview",
response_model=UserDetail,
messages=[
{"role": "user", "content": "Extract Jason is 25 years old"},
]
)
return user
import openai
import json
def extract_user() -> dict:
completion = client.chat.completions.create(
model="gpt-4-turbo-preview",
tools=[
{
"type": "function",
"function": {
"name": "ExtractUser",
"description": "Correctly extracted `ExtractUser` with all the required parameters with correct types",
"parameters": {
"properties": {
"name": {"title": "Name", "type": "string"},
"age": {"title": "Age", "type": "integer"},
},
"required": ["age", "name"],
"type": "object",
},
},
}
],
tool_choice={"type": "function", "function": {"name": "ExtractUser"}},
messages=[
{"role": "user", "content": "Extract Jason is 25 years old"},
],
) # type: ignore
user = json_loads(completion.choices[0].message.tool_calls[0].function.arguments)
assert "name" in user, "Name is not in the response"
assert "age" in user, "Age is not in the response"
user["age"] = int(user["age"])
return user
部分提取¶
我们也支持部分提取,这对于流式传输不完整的数据很有用。
import instructor
from instructor import Partial
from openai import OpenAI
from pydantic import BaseModel
from typing import List
from rich.console import Console
client = instructor.from_openai(OpenAI())
text_block = "..."
class User(BaseModel):
name: str
email: str
twitter: str
class MeetingInfo(BaseModel):
users: List[User]
date: str
location: str
budget: int
deadline: str
extraction_stream = client.chat.completions.create(
model="gpt-4",
response_model=Partial[MeetingInfo],
messages=[
{
"role": "user",
"content": f"Get the information about the meeting and the users {text_block}",
},
],
stream=True,
)
console = Console()
for extraction in extraction_stream:
obj = extraction.model_dump()
console.clear()
console.print(obj)
这将输出以下内容
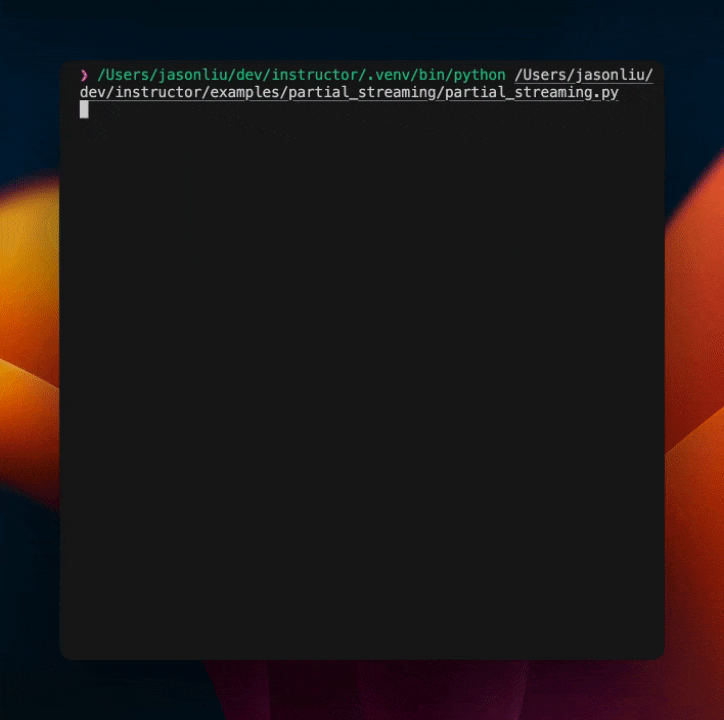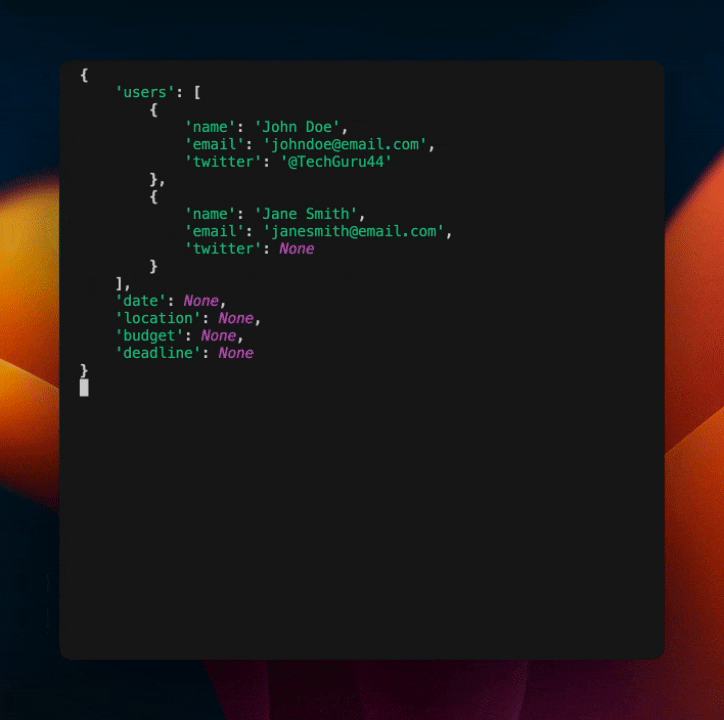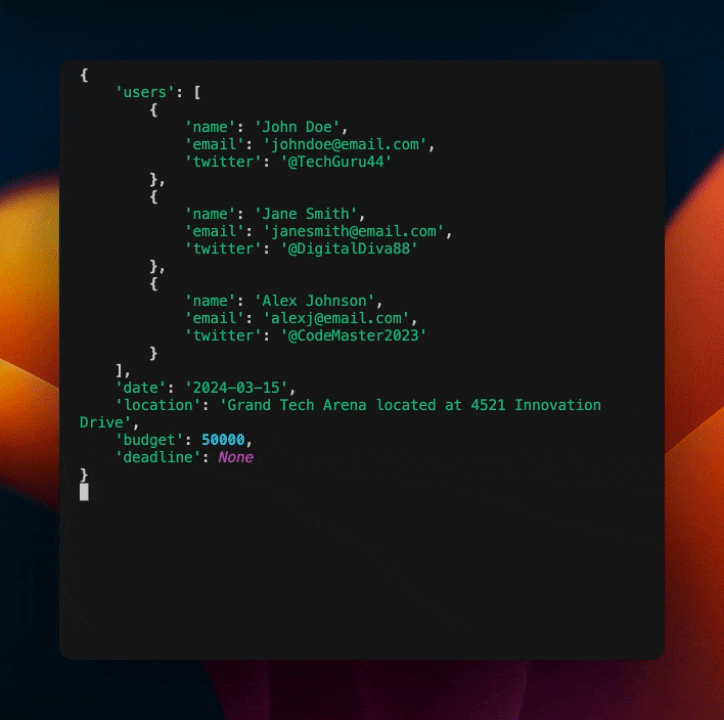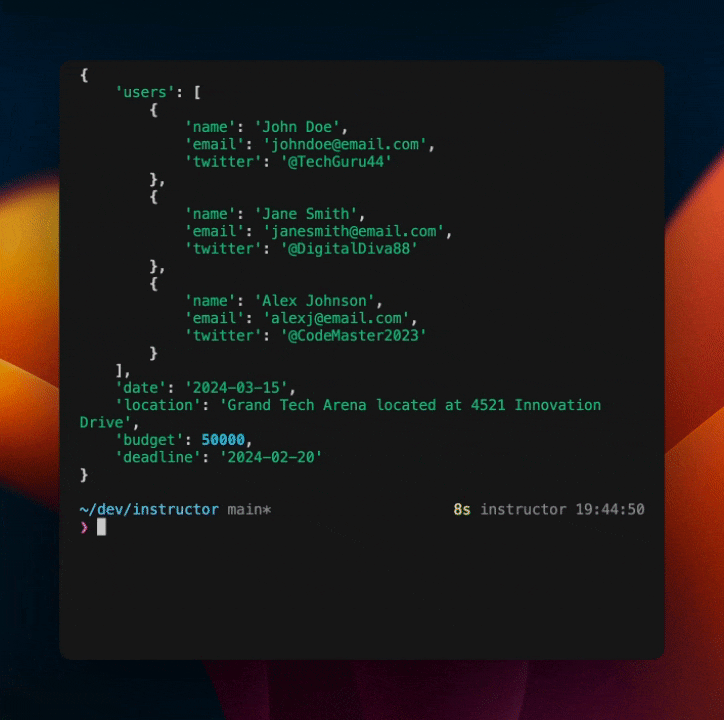
如你所见,我们在模型中内置了自我纠正机制。这是一种强大的方式,可以使你的模型更加健壮且不易出错,而无需包含大量额外的代码或 Prompt。
可迭代对象和列表¶
我们还可以通过定义 Iterable[T] 类型来在 token 流入时生成任务。
让我们来看看同一个类的一个实际例子
from typing import Iterable
Users = Iterable[User]
users = client.chat.completions.create(
model="gpt-4",
temperature=0.1,
stream=True,
response_model=Users,
messages=[
{
"role": "system",
"content": "You are a perfect entity extraction system",
},
{
"role": "user",
"content": (
f"Consider the data below:\n{input}"
"Correctly segment it into entitites"
"Make sure the JSON is correct"
),
},
],
max_tokens=1000,
)
for user in users:
assert isinstance(user, User)
print(user)
#> name="Jason" "age"=10
#> name="John" "age"=10
简单类型¶
我们也支持简单类型,这对于提取简单的值(如数字、字符串和布尔值)非常有用。
验证错误时自我纠正¶
由于 Pydantic 自带的验证模型,可以轻松地向模型添加验证器来纠正数据。如果我们运行这段代码,将会因为名称不是大写而得到一个验证错误。虽然我们可以包含一个 Prompt 来修复这个问题,但我们也可以直接向模型添加一个字段验证器。这将导致两次 API 调用,因此请确保在添加验证器之前尽力使用 Prompt 进行修正。
import instructor
from openai import OpenAI
from pydantic import BaseModel, field_validator
# Apply the patch to the OpenAI client
client = instructor.from_openai(OpenAI())
class UserDetails(BaseModel):
name: str
age: int
@field_validator("name")
@classmethod
def validate_name(cls, v):
if v.upper() != v:
raise ValueError("Name must be in uppercase.")
return v
model = client.chat.completions.create(
model="gpt-3.5-turbo",
response_model=UserDetails,
max_retries=2,
messages=[
{"role": "user", "content": "Extract jason is 25 years old"},
],
)
assert model.name == "JASON"